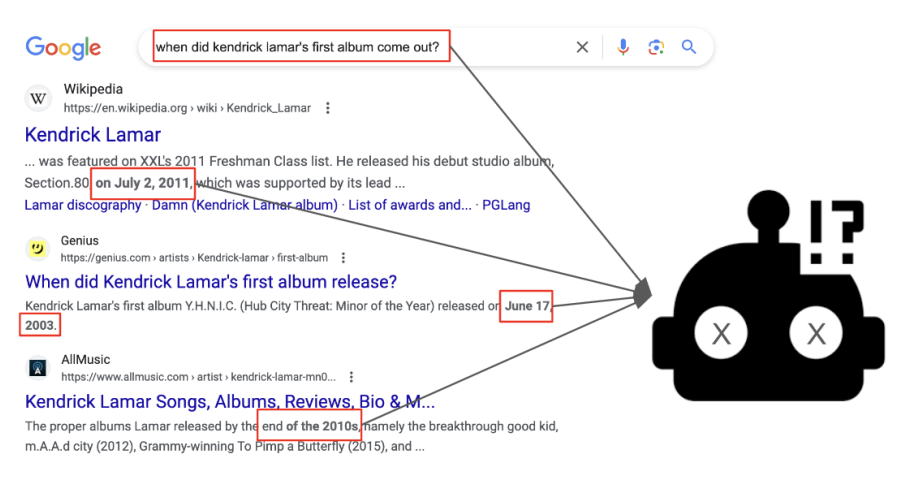
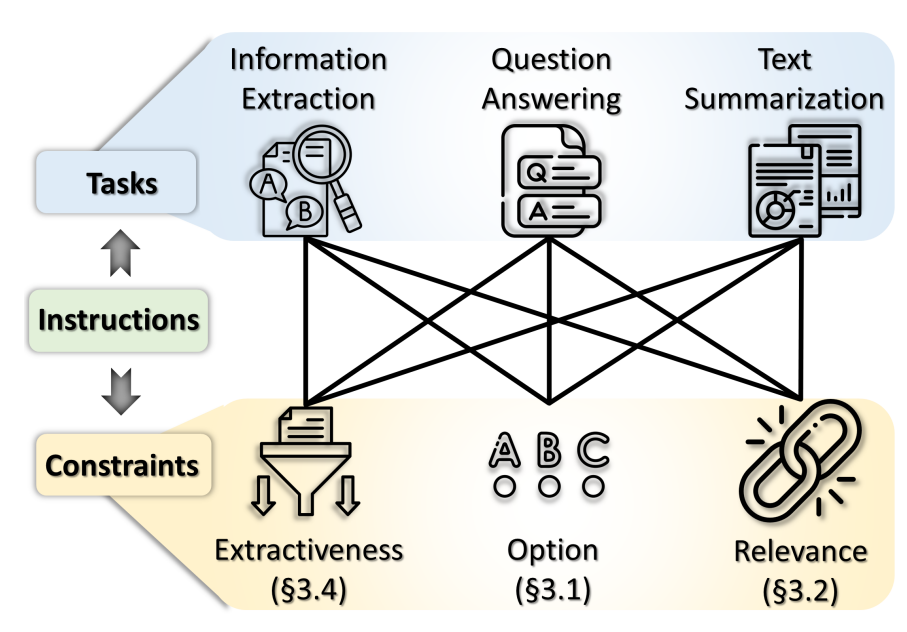
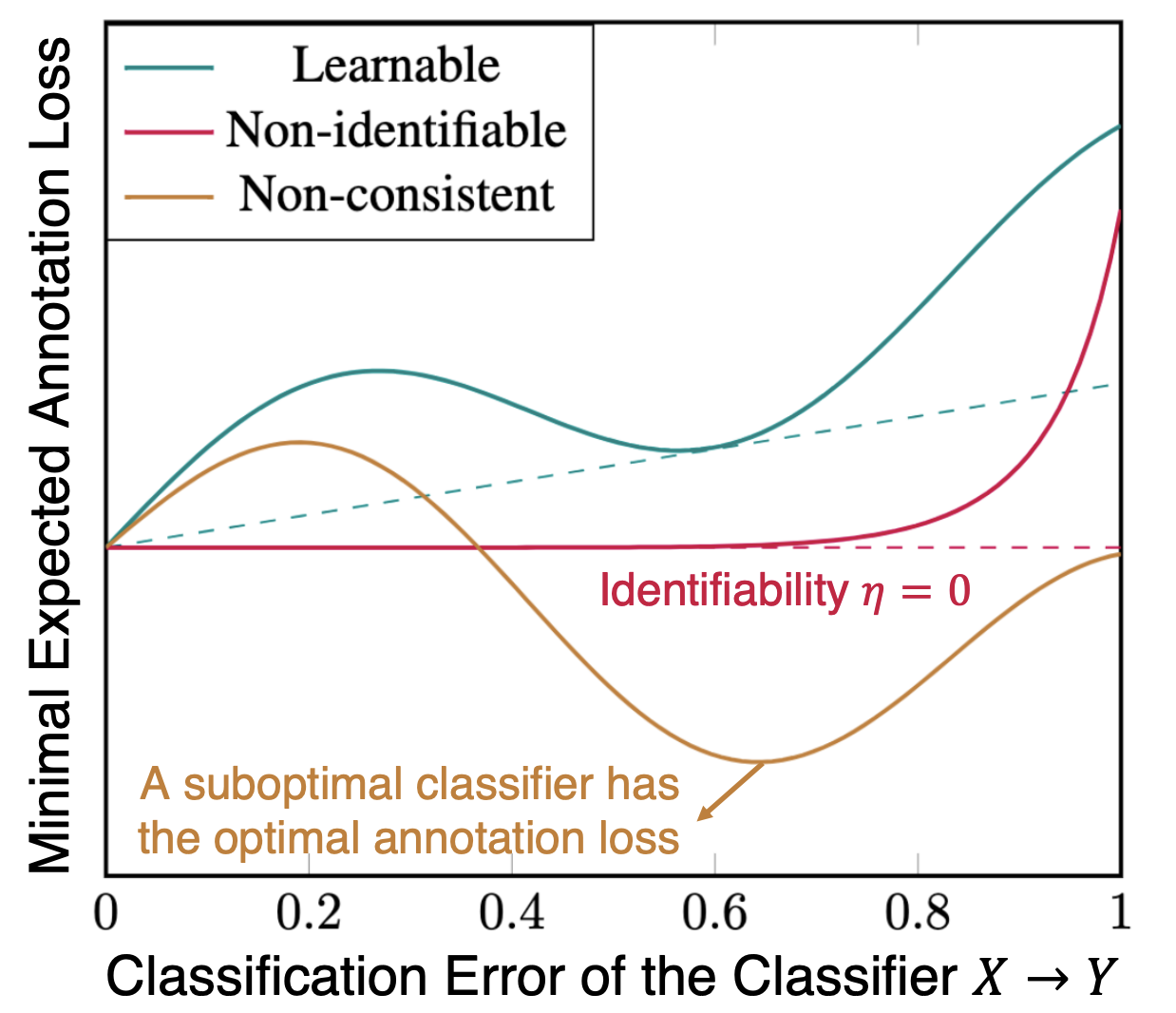
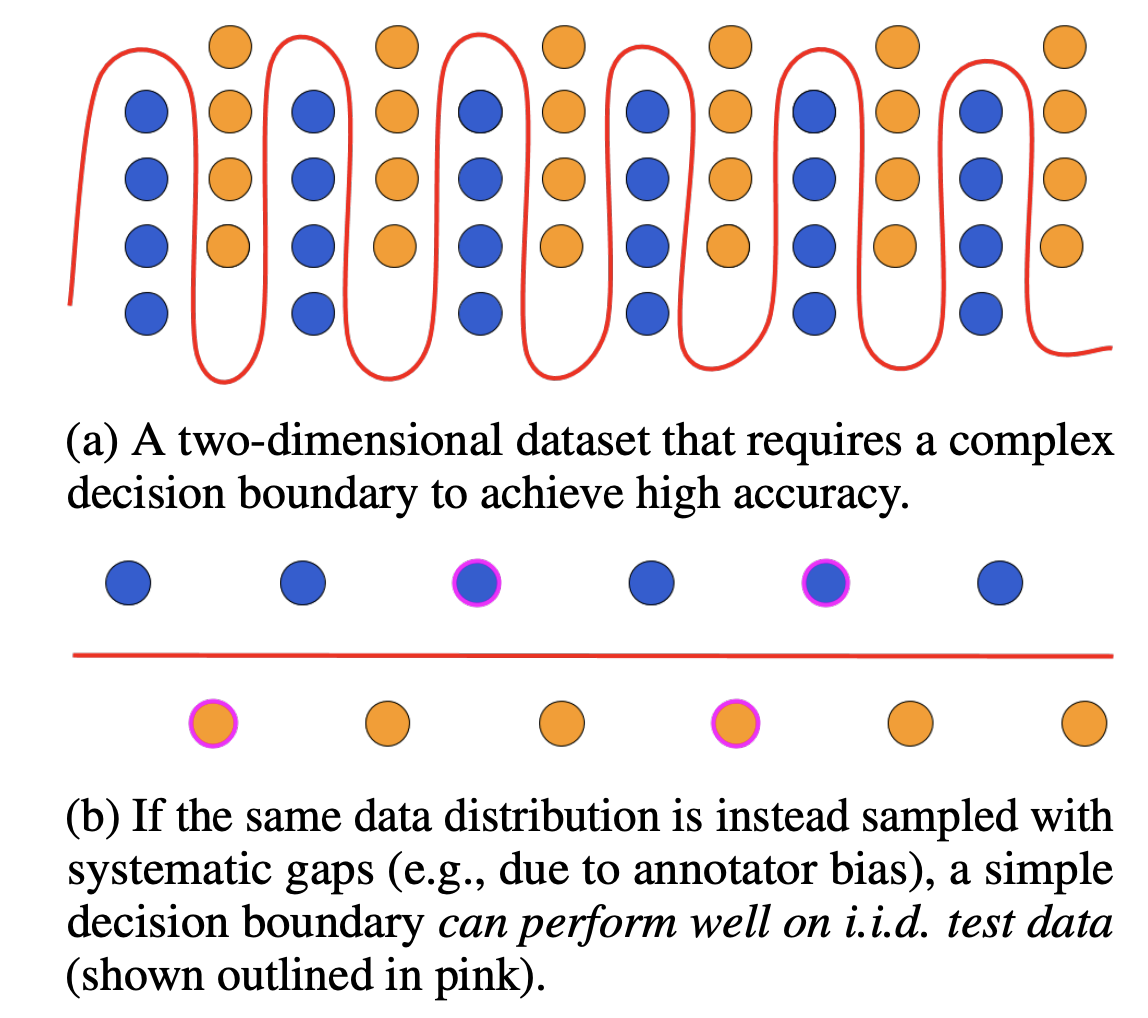
@article{liu2024open,title={Open domain question answering with conflicting contexts},author={Liu, Siyi and Ning, Qiang and Halder, Kishaloy and Xiao, Wei and Qi, Zheng and Htut, Phu Mon and Zhang, Yi and John, Neha Anna and Min, Bonan and Benajiba, Yassine and Roth, Dan},journal={Findings of NAACL},year={2025}}
LLMs
Aligning to Constraints for Data-Efficient Language Model Customization
Fei Wang, Chao Shang, Shuai Wang, Sarthak Jain, Qiang Ning, Bonan Min, Vittorio Castelli, Yassine Benajiba, and Dan Roth
@article{wang-etal-2025-aligning,title={Aligning to Constraints for Data-Efficient Language Model Customization},author={Wang, Fei and Shang, Chao and Wang, Shuai and Jain, Sarthak and Ning, Qiang and Min, Bonan and Castelli, Vittorio and Benajiba, Yassine and Roth, Dan},journal={Findings of NAACL},year={2025}}
2022
NLP
PInKS: Preconditioned commonsense inference with minimal supervision
Ehsan Qasemi, Piyush Khanna, Qiang Ning, and Muhao Chen
@article{qasemi2022pinks,title={PInKS: Preconditioned commonsense inference with minimal supervision},author={Qasemi, Ehsan and Khanna, Piyush and Ning, Qiang and Chen, Muhao},journal={AACL},year={2022}}
NLP
Answer Consolidation: Formulation and Benchmarking
Wenxuan Zhou, Qiang Ning, Heba Elfardy, Kevin Small, and Muhao Chen
Current question answering (QA) systems primarily consider the single-answer scenario, where each question is assumed to be paired with one correct answer. However, in many real-world QA applications, multiple answer scenarios arise where consolidating answers into a comprehensive and non-redundant set of answers is a more efficient user interface. In this paper, we formulate the problem of answer consolidation, where answers are partitioned into multiple groups, each representing different aspects of the answer set. Then, given this partitioning, a comprehensive and non-redundant set of answers can be constructed by picking one answer from each group. To initiate research on answer consolidation, we construct a dataset consisting of 4,699 questions and 24,006 sentences and evaluate multiple models. Despite a promising performance achieved by the best-performing supervised models, we still believe this task has room for further improvements.
@article{zhou-etal-2022-answer,title={Answer Consolidation: Formulation and Benchmarking},author={Zhou, Wenxuan and Ning, Qiang and Elfardy, Heba and Small, Kevin and Chen, Muhao},journal={NAACL},year={2022}}
@article{NEURIPS2020_67ff32d4,author={Wang, Kaifu and Ning, Qiang and Roth, Dan},journal={NeurIPS},title={Learnability with Indirect Supervision Signals},year={2020}}
NLP
Evaluating models’ local decision boundaries via contrast sets
Matt Gardner, Yoav Artzi, Victoria Basmova, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar, and 2 more authors
@article{gardner2020evaluating,title={Evaluating models' local decision boundaries via contrast sets},author={Gardner, Matt and Artzi, Yoav and Basmova, Victoria and Berant, Jonathan and Bogin, Ben and Chen, Sihao and Dasigi, Pradeep and Dua, Dheeru and Elazar, Yanai and Gottumukkala, Ananth and others},journal={Findings of EMNLP},year={2020}}
2019
NLP
"Going on a vacation" takes longer than" Going for a walk": A Study of Temporal Commonsense Understanding
@article{zhou2019going,title={"Going on a vacation" takes longer than" Going for a walk": A Study of Temporal Commonsense Understanding},author={Zhou, Ben and Khashabi, Daniel and Ning, Qiang and Roth, Dan},journal={EMNLP},year={2019}}